�Ҷԣ�ά��������˼����һ�£�������һ��µĶ����?
) `) i& V; r1 ^0 ?7 r! ~ C! }9 s�����У���롣Ϊ�˱������⣬��������һ�����ͼ��
; _) C$ c( p$ _, F" j3 @4 I0 b����һ�ţ��أ����ص�ͼ���⣴�أ����ش���һ����ĸ��Ҳ���ǣ�����ά�룬ͬʱ��Ӧһ�����ӣãɣ��롣 . }5 B# c# N; [$ b
. k! n# g" V# M) {' L- f+ w
ΪʲôҪʹ��У�����ء���ʵ��Ϊ˼��һ�¾ͺ������뵽�����ǵģ�ά������ʾ���б�������Ϸ�����ϵģ����Բ��ɱ�����ܷ�����ά�����ɫ��ͱ�����ɫ��ͬ����������һ������ԭ��Ӧ�������ģ����DZ�������ɫ����ɫ�����ɫ������ͬ�Ļ������ǵģ�ά��ʶ�����ͻ�������ʶ��Ϊ��ɫ�㣬�����Ļ���������ά���ʶ����ˡ�
- p, _5 I( r" ~6 z6 O; W& w7 J
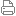
5 G! K0 c6 v- h# {" L����������һ��ʾ��ͼ������������������һ����Ļ�������������������Ļ�����ʹ�ã����صģ�ά�룬����ͼ�ϵ�dz��ɫ�ĵ㣮������������Ļ���Ҫʹ�ã����صģ�ά�룮У�����ʾ������ɫ��ĸ�������Ӧ�ģ�ʹ�ã����صģ�ά���ʱ��ʹ�ã����ص�У���룬ʹ��9���صģ�ά���ʱ��ʹ��4���ص�У���룮��Ϊ�������������ֿ��Ա�ʾ���������������������ֿ��Ա�ʾ���������� 0 _; r8 v7 q0 V# R9 T
3 _- {5 ]$ c; J�����ǵ�ʶ�������У����ͣ�ά�����ɫ��ĸ�����ͬ��ʱ����������磬�Ӷ��ҵ�������ʶ����Ǹ��ɣġ� & @0 n5 }" g8 @ R* W, s f! n
8 x8 j+ E5 K: l1 d
---------------------------------------
0 U4 X7 \( e: y! D0 A: P2009.6.6 ���� 3 q# }/ m* {: e" i% ^" {
. e% v( v$ J# O, b) p7 B( q
���˷�ţ��û����ȫ����,������������û�б������. % t7 M7 G0 t$ K% w$ B
���ٲ���˵��һ��. & \% q8 E% j+ D! f2 S
$ X+ Y9 Z+ q9 {+ B( [3 M
���Dz�����һ���ȷ�,���ǰ�ͼƬ��ģ��tga����Ϊһ������������ÿ�����ص�ǰ3���ֽ� FF FF FF�ͺñ��Ǻ����IJ��������βΡ� 0 {' ]4 V. Q0 U+ m( B, ]
��ôʵ����ʲô�ء�ʵ�����趨����Ϸ���������������ɫ����ô����ֵ��ʲô�أ�����ֵ����ʾ����Ϸ�����ϵ����塣����ʵ�Σ�Ҳ������
- E" k$ H8 t, |3 t) j( p2 _����������ɫ�IJ�ͬ����ô����ֵ��Ҳ���������ʾ������������ɫҲ��ͬ��
/ H$ H; W( J; e: Q$ G$ c�����Ӧ�ñȽ��������⣬��������˵����ţ���������ĵط���
. T: z O9 Y2 u. _- w6 ^��˵��ɫ����FF FF FF FF��������FF FF FF 00���������ָtgaͼƬ�ֿ���������������ġ� * N# u3 B) c" L6 k3 n. M
����Կ���һ���������ڲ�����Щ���ݡ� + U' f: ?, u! e: {$ A3 b) j' Q
һ�����屻��ʾ�������൱����ʾ�����������tgaͼƬ�ֿ⺯����ֵ�� 0 ^# I: }) K; _ E2 m* z5 W
���������趨��������ɫ�� AA AA AA,��ô�������ɫ�㱻�任ΪAA AA AA FF,�����������Ϸ�����϶�Ӧλ�õ�������ɫ��ʾ������
# }( ?6 q$ p1 ?, a7 ~+ R���ԣ�һ�����屻��ʾ����Ļ���Ժ��Ǹ�3X3��С���������ɫ״���� l2 C- u N: V. b! G9 L
/ J: E% W$ A& J0 E���� ��ɫ����FF FF FF FF��������FF FF FF 00
% K- S- o' z$ u���� ��ɫ����AA AA AA FF����ɫ���� ��Ϸԭ�����ص���ɫ ��32bit�� 6 ]5 B5 R! ~$ ^0 ~: i6 w- H
% {+ F7 K% W T% d& \���Ǵ�log����Կ�������Ϸ��������32bitģʽ�µġ�
; E& v5 Z) \2 r% k( U' {22:11:58: D3D9 : Created D3D9 Rendering Window 'Ankh - Heart of Osiris' : 1024x768, 32bpp
- D3 @: Y" J6 S; j, S
, s/ b& d) u* O9 J) d�ã������ٻع�ͷ��������������ɫ�����⣬���͵����Ӧ�������˰ɡ� ( w. A0 G, c5 g# e' h
9 q1 Y) _) M* Q5 `! Y
�Ҿ�û�����������ص��ӵ��������Ժ���ô�ٶ�ȡ������
7 b" T: @( ~$ k3 {$ E0 b/ v$ S�����ص��ӵ��������Ժ�Ͳ��������ˣ�������Ȼ���������������ɫ���ֿ����� " q% [; Z: F- g+ i% x4 G
Ϊ�˷�ֹͨ����������������Ϸԭ�������ص���ɫ���������ɫһ��������������У���롣
' s1 b+ j7 u1 ~! {6 [ uУ����Ķ�ȡҲ�ܼ�У�������������ͬһ����ɫ��ʾ�ģ��ȷ�˵������ɫ��AA AA AA FF����У�������ɫҲ��AA AA AA FF�� $ W) x2 r/ P5 q2 r
: Q' |* _) _" m! u: A0 x7 S0 k& S�����ͼ�Ͽ��Կ�����У������ʾ��λ���ǹ̶��ģ��������ǿ����жϳ�У�����3��4�������м�������AA AA AA FF��У�����ÿһλ����ɫ��AA AA AA FF�Ƿ���ͬ��״̬�����Կ���0��1�������Ϳ��Ա�ʾ8��16��״̬����ʾ3X3 2ά���еĺ��趨������ɫ��ͬ�ĵ�ĸ�����������
; q( v6 N& r5 A/ F- W������ʵ�ʵ�3X3 2ά���еĺ��趨������ɫ��ͬ�ĵ�ĸ�����ͬ����ô�ͱ�ʾУ�鲻ͨ������ʶ�����
& a6 d& B2 e; F; ?* r5 N/ D! F R6 a* \# F2 ^, o
����Ҳ����˵��У���뱾����ʶ���������ô�죿
, v8 U) q) i, J' s; E& q+ A% D" X2 k��������Ǵ��ڵġ�У���벻��У���ȫ���Ĵ����ǴӸ�����˵����У������ִ��� # g0 {/ C! q! T" a5 \
Ϊʲô��ô˵�أ���Ϊ��������ʶ������ֻ���ǣ�ij���㱻��ʶ���ˡ�����˵��ij������ָ����Ϸ�����Ϻ�������ɫ��ͬ�ĵ㡣
: F( f9 M, S$ S3 V���ԣ�У����У�鲻���������ֻ��һ�֣������У�����2ά�붼����ʶ���˼����㡣Ȼ������У�����ʾ����ֵ�ʹ����2ά��ĺ�������ɫ��ͬ�ĵ������������ͬ���������Ӧ���Ǻܵ��ʵġ�
/ \: P2 k `/ i- S& W7 n: O. p5 C- H5 G3 {! j! x T' S7 N
���Ҫ˵���ǣ�У����ֻ����Ϸ���Խ����ã�������������ʱ��ð�У������proxy dll��ȥ��������Ӱ���ٶȡ�tgaͼƬ�������Բ��ģ�����xml�ļ�Ҫ�ģ���ÿ����ĸ�Ļ��ָĶ�һ�¡�
/ R; Z& i) p' v7 m( R$ I��4X4 ��Ϊ 3X3������˵Ҫ��x,y width,heigh.
0 s: G$ B4 q; s/ O$ C6 |- z: v0 j# S/ p+ a
-------------------------------------------------------- - I+ X9 k+ f3 \) S& U0 v; q/ B: H
2009.6.15 ���� . `, \8 L" g: ^% \0 n( s% n3 n- F( I
���������һ��2ά��IJ��֣���ð�����µ��뷨�� 7 L) S" Q9 q8 j& z
�����ʵ�ֵĻ����ܰ����еķ����������������Ƚϸ��ӵ�2ά�룬����������ʶ����Ϊ0��
. Z `3 r0 Y9 `* G4 n7 M( b( T4 T˵�����ܼ����ǰ�ԭ����ʾ����Ļ�в�����Ļ����Ų�����ײ��ĺ�ɫ�����Ͼ����ˡ�
# l# n* C( Y) m7 P8 m% z6 W3 d/ O������ôŲ��ֻҪ��xml������y���������ֵ�����ˡ�
& y1 ^9 d9 F8 D6 x* [" e& @# Xһ�������ܰ�ԭ����ʾ����Ļ�в�����Ļ����Ų�����ײ��ĺ�ɫ�����ϵĻ������Ǿ�����ԭ��������������жϷ������ж��ˡ��Ƚϸ��ӵ�2ά��Ҳ���������ˡ� 6 X1 l. e, {( [! A
��Ȼ�������жϳ�ID�Ժ���proxy dll�л���Ҫ�Ѷ�Ӧ������Ļ��ʾ����Ļ�в��ġ�
1 ?* E, }* Q- e& _8 v }3 y: `5 x������Ļ���ж϶�ͳһ���������ϣ�����ֻҪ�ѳ����˵�ID�������ID����Ӧ��һ��12��13λ���������ϼ��ɡ� |









 ������ 2009-6-5 18:52
������ 2009-6-5 18:52
![��1126�š��鼮������3������ʽ����ChinaAVG������[858MB]](data/attachment/forum/202411/08/185805cvi1r0xgixdpzif6.jpg)

 QQ���Ѻ�Ⱥ
QQ���Ѻ�Ⱥ QQ�ռ�
QQ�ռ� ��Ѷ��
��Ѷ�� ��Ѷ����
��Ѷ���� �ղ�
�ղ� ����
���� ������
������ �ܲ
�ܲ

 ¥��
¥�� ������ 2009-6-6 13:06
������ 2009-6-6 13:06
