好吧,既然007不相信我的分析,那我就用实例来说明吧。
3 p8 D% M9 b' S' R' G以font目录中的font_game_menu_buttons为例,用16进制工具打开它,我们就能看到:
5 o L6 R9 d: A( l1 B, ROffset 0 1 2 3 4 5 6 7 8 9 A B C D E F9 v, B0 g2 R0 B$ V
# d0 X& M8 N' X. r* ^+ ^* ]00000000 16 00 00 00 66 6F 6E 74 5F 67 61 6D 65 5F 6D 65 ....font_game_me. A; p9 N8 q$ F( h: ?
00000010 6E 75 5F 62 75 74 74 6F 6E 73 21 00 00 00 50 04 nu_buttons!...P.
Z/ m0 l0 Y( D' O6 G00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
) E- F+ X" f. `4 }. Z; N00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................! e- T$ q5 j) S# [% a l8 ]
8 F7 \+ t* G+ y3 F
第一个字节0x16表示每个字符的占位是24个字节,偏移量0x1e开始的4个字节0x0450代表这个索引表一共有这么多个字符。2 v# x x0 G8 R4 p+ e; U$ S1 n. N: y! o
4 a4 p* P0 V1 q7 y* {& x
再跳到数据部分:
: M! v: M) X0 C; a! y
. ]$ R/ m( P( _' o- A) u# xOffset 0 1 2 3 4 5 6 7 8 9 A B C D E F; k5 v; w9 `3 f
4 Q6 C& v, o5 i" A2 G* G00000320 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................1 [; i& k% u' ~
00000330 00 00 00 00 00 00 00 00 00 00 6A 01 00 00 AE 00 ..........j...?' |# j9 V9 K- v$ ?1 s9 q7 E" e3 M
00000340 00 00 6F 01 00 00 CF 00 00 00 00 00 00 00 00 00 ..o...?........( Y2 R- E7 v0 r$ L# y: c0 W
00000350 00 00 EF 01 00 00 AE 00 00 00 F5 01 00 00 CF 00 ..?..?..?..?
! ]# j, W! D# C3 q6 g00000360 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
3 S9 `6 i' M3 Z: H+ y00000370 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................7 E! I3 m- P. u3 A0 S9 S
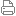
: z- _4 v9 p2 j0 m& _5 j# z0x016A, 0x00AE,0x016F,0x00CF分别是左上角的横纵坐标,右下角的横纵坐标,我们看看这个范围在对应的图片中是什么:2 i q' O, i) B, ?" D( n
2 g3 m8 I' w- S: f/ e9 n
4 R, N) v) _! t2 T L% i1 b; \7 ~
从图中可以看出,这个范围对应的是字符"!"。同样,跳过8个字节的00后,0x01EF, 0x00AE, 0x01F5, 0x00CF也能对应出相应的字符。
7 _2 w& f; |1 F4 C( S; C( z
: X7 g" b8 H& U为此,我专门写了一个小工具来查看显示顺序与图片之间的关系。这个工具只能证明字符的存储是按照ASCII顺序,而不能说明是从哪个字符开始的。$ g- ^, ^# \& |1 w4 v& s
7 D* A. v3 k l/ N, T9 L4 k当然,这个工具中我做了一些处理。因为第一个显示的字符是"!",所以我将它的ASCII码定为33了。
1 a8 d* Z6 g9 O2 G4 F我们点击SPIN的上下箭头,调整ASCII码,就可以看到该顺序在索引中取出的是什么字符图片。 |




 发表于 2009-5-10 09:03
发表于 2009-5-10 09:03
![【1126号】书籍旅行者3:哥特式故事ChinaAVG汉化版[858MB]](data/attachment/forum/202411/08/185805cvi1r0xgixdpzif6.jpg)

 QQ好友和群
QQ好友和群 QQ空间
QQ空间 腾讯微博
腾讯微博 腾讯朋友
腾讯朋友 收藏
收藏 分享
分享 很美好
很美好 很差劲
很差劲

 楼主
楼主




